Keylearnings:
- Was ist die Aufgabe des http Protokolls?
- Wie ist das http Protokoll aufgebaut?
- Was ist eine Session?
- Was sind http Abfragemethoden?
- Was ist der http Statuscode?
- Das HTTP-Protokoll in Aktion!
Heute schon im Internet gesurft?
Okay, blöde Frage. Das merke ich selber. Sonst wärst du schließlich nicht hier.
Aber hast du dir die Adresse in deinem Webbrowser mal genauer angesehen?
Egal welche Seite du im Internet aufrufst. Die Adresse, die du in den Browser eintippst beginnt immer mit http.
Und genau hierüber wollen wir uns in diesem Artikel unterhalten.
Wofür steht http?
Das ist der einfache Teil! HTTP steht für Hyper-Text Transfer Protocol.
Doch was hat es damit auf sich?
Welche Aufgabe hat das http Protokoll?
Im Internet gibt es zwei Arten von Teilnehmern. Die Server und die Clients.
Der Server stellt einen Dienst zur Verfügung, den der Client nutzen kann.
Dieses Prinzip heißt Client Server Modell.
Nach diesem Prinzip arbeitet nicht nur das Internet sondern auch der Pizzaservice.
Du als Kunde des Pizzaservice übernimmst die Rolle des Clients und der Pizzaservice ist der Server.
Bitte stell dir jetzt folgendes Szenario vor!
DVD Abend bei dir zu Hause! Natürlich möchtest du auch was essen.
Daher stellst du eine Anfrage, den sogenannten Request, an den Pizzaservice, in der festgelegt ist, welche Pizza, in welcher Größe du wann haben möchtest.
Daraufhin antwortet der Pizzaservice, mit einem sogenannten Response, und teilt dir mit, ob, wann und zu welchem Preis die gewünschte Pizza geliefert werden kann.
Und genau so funktioniert auch das Internet
Auch im Internet erstellt der Client (das bist du) einen Request an einen Server (z.B. google), der mit einem Response auf den Client-Request antwortet.
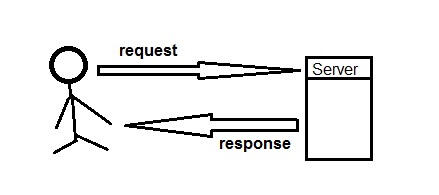
Aufgabe des HTTP Protokolls ist es einen Standard für die Struktur des Requests und den Response zu definieren, sodass Server und Client miteinander kommunizieren können.
Der Aufbau des HTTP Protokolls
Das http Protokoll schreibt vor, dass sowohl Requests als auch Responses aus einem Kopfteil für Metainformationen und einem Bereich für die Nutzdaten bestehen.
Neben einem Zeitstempel, der das Datum und die Uhrzeit eines Request bzw. einer Response beinhaltet, befinden sich im Headerteil eines Request Informationen über den vom Client verwendeten Internet-Browser (Chrome, Firefox, Safari etc.) und im Headerteil der Response über den verwendeten Web-Server (Apache, nginx).
Des Weiteren enthält der Header noch den sogenannten Content-Type, der angibt von welchem Typ die Nutzdaten sind.
Mit Hilfe des Content-Types kann der Client bzw. der Server bestimmen, mit welchem Programm die empfangenen Nutzdaten weiterzuverarbeiten sind.
Beinhaltet der Content-Type beispielsweise die Information, dass es sich bei den Nutzdaten um ein PDF Dokument handelt, dann bedeutet das für den Client, dass die Nutzdaten mit einem PDF Viewer wie dem Adobe Acrobat Reader weiterzuverarbeiten sind.
Wofür das HTTP Protokoll nicht zuständig ist!
Das HTTP Protokoll ist der Application Layer Schicht im OSI Schichtenmodell zu zuordnen. Darüber wollen wir uns jetzt aber keinen Kopf machen. Wichtig ist nur die Konsequenz dieser Tatsache.
Aufgabe des HTTP Protokolls ist nicht der Transport der Requests bzw. der Reponses von A nach B. Hierfür ist das sogenannte TCP/IP Protokoll zuständig.
Das HTTP Protokoll hat nur dafür zu sorgen, dass der Server die Requests und der Client die Responses interpretieren kann.

Was ist eine http Session?
Soweit so gut. Wir können also mit Hilfe des http Protokolls eine Anfrage an den Server stellen und erhalten eine Antwort.
Aber reicht uns das?
Nicht wirklich! Denn nachdem wir die Antwort vom Server erhalten haben, hat uns dieser bereits wieder vergessen. Der Fachmann spricht daher davon, dass das http Protokoll ein zustandsloses Protokoll ist.
Einverstanden! Um eine Wetterabfrage-App zu schreiben reicht uns das.
Aber was machen wir wenn unsere Abfragen voneinander abhängen? Wie zum Beispiel bei einer Bestellung in einem Webshop.
In einem Webshop können wir erst etwas bestellen, wenn wir uns mit unseren Kundendaten angemeldet haben.
Egal, ob wir einen Artikel in unseren Einkaufswagen legen, unsere Zahlungsinformationen eingeben oder eine Bestellung abschicken wollen. In jedem Fall muss der Server überprüfen, ob wir uns vorher korrekt eingeloggt haben.
Und das geht nur, wenn der Server sich an uns „erinnert“ und uns eindeutig identifizieren kann.
Die Lösung sind sogenannte Session ID’s.
Hierbei sendet der Server beim ersten Response eine eindeutige ID an den Client, über die dieser dann eindeutig identifiziert werden kann.
Der Client speichert die Session ID entweder als Cookie oder verwendet eine als URL rewritting bezeichnete Technik.
Bei jedem weiterem Request kann uns der Server, dann anhand der Session ID, wiederkennen und überprüfen, ob wir uns zuvor mit einem bereits erfolgten Request korrekt eingeloggt haben.
Aus Sicherheitsgründen hat eine Session in der Regel eine beschränkte Gültigkeitsdauer, nach der sie automatisch beendet wird.
Die http Anfragemethoden
Wenn du jemanden um einen gefallen bittest, musst du sagen was du willst. So ist es auch wenn ein Client eine Anfrage an den Server stellt.
Ein Request muss dem Server mitteilen, ob wir Daten lediglich anfragen, oder ob wir Daten liefern, die der Server verarbeiten muss.
Für diesen Zweck definiert das http Protokoll unterschiedliche Abfrage-Methoden.
Die wichtigsten sind GET, POST, PUT und DELETE.
Um Daten abzufragen verwenden wir die GET Methode. Ein klassisches Beispiel ist die Anfrage an eine Suchmaschine. Wenn wir beispielsweise bei bing das Internet nach dem Begriff „Mercedes Benz“ durchsuchen, verwenden wir die GET Methode.
Werfen wir einen Blick auf die bei der Abfrage erzeugte URL.
Bei der GET Methode haben wir die Möglichkeit URL Parameter zu setzen, die auf der Serverseite ausgewertet werden können.
http://www.bing.com/search?q=Mercedes+Benz
Bei bing besteht der URL Parameter aus dem Suchbegriff, nach dem wir suchen.
Die POST Methode wird verwendet um Daten zu senden, die der Server verarbeiten muss. Ein klassisches Einsatzgebiet dieser Methode ist die Übertragung von Daten eines Adress-Eingabeformulars an den Server.
Mit Hilfe der PUT Methode können wir neue Ressourcen auf dem Server anlegen oder eine bereits vorhandene verändern. So können wir beispielsweise eine Bilddatei auf den Server übertragen.
Besonderheit hierbei ist, dass die PUT Methode eine bereits existierende Ressource überschreibt, wenn diese den gleichen Namen hat wie die zu übertragende Ressource.
Zu guter letzt definiert das http Protokoll noch die DELETE Methode, mit der wir Ressourcen auf dem Server löschen können.
Der http Servercode
Im schlimmsten Fall kann es in unserem Pizza-Beispiel passieren, dass der Pizzabäcker nicht alle Zutaten auf Lager hat und uns die gewünschte Pizza nicht liefern kann.
Dasselbe kann uns auch bei einem Request passieren, wenn wir eine Ressource anfordern, die es auf dem Server nicht gibt.
Für diesen Fall definiert das http Protokoll sogenannte Fehlercodes.
Versuchen wir auf eine nicht existierende Ressource zu zugreifen, enthält die Server-Response den Fehler 404. Ist der Zugriff erfolgreich erhalten wir den Statuscode 200.
Eine vollständige Übersicht aller http Statuscodes findest du hier.
Das http Protokoll in Aktion
Zugegeben bisher ist das alles theoretisch und abstrakt. Deshalb wollen wir uns im folgenden einen echten Client-Request und die zugehörige Server-Response ansehen.
In dem Moment, in dem du beispielsweise die Adresse www.codeadventurer.de/hello.htm in den Browser eingibst erzeugt der Client folgenden GET Request.
1: GET /hello.htm HTTP/1.1 2: User-Agent: Mozilla/6.0 (compatible; MSIE5.01; Windows 10) 3: Host: www.codeadventurer.de 4: Accept-Language: de 5: Accept-Encoding: gzip, deflate 6: Connection: Keep-Alive
In Zeile Eins wird die Abfrage-Methode (in diesem Fall ein GET) und der Name der gewünschten Ressource (hello.htm) festgelegt.
Die darauf folgenden Zeilen enthalten Informationen, über den verwendeten Browser, die Domäne des Host und die verwendete Sprache.
Auf diesen Request antwortet der Server mit folgender Response:
1: HTTP/1.1 200 OK 2: Date: Mon, 03 Oct 2016 12:28:53 GMT 3: Server: Apache/2.2.14 (Win64) 4: Last-Modified: Mon, 03 Oct 2016 13:15:56 GMT 5: ETag: "34aa387-d-1568eb00" 6: Vary: Authorization,Accept 7: Accept-Ranges: bytes 8: Content-Length: 88 9: Content-Type: text/html 10: Connection: Closed 11: <html> 12: <body> 13: <h1>Hello, World!</h1> 14: </body> 15: </html>
Zunächst fällt die Aufteilung in Kopf und Nutzdaten auf. Der Kopf befindet sich in den Zeilen 1 bis 10 und enthält unter anderem den Statuscode, einen Zeitstempel, Informationen über den verwendeten Webserver und den Content-Type, der angibt, dass es sich bei den Nutzdaten um ein HTML Dokument handelt.
Den Nutzdatenteil finden wir in den Zeilen 11 bis 15. Dieser besteht aus dem zu übertragenen HTML Dokument.
Fazit: Ziel dieses Artikels war es dir einen groben Überblick über das http Protokoll zu geben.
Das http Protokoll stellt Regeln zur Verfügung damit Server und Client mit Hilfe von Requests und Responses miteinander kommunizieren können. Bei dem http Protokoll handelt es sich um ein zustandsloses Protokoll was in vielen Web-Anwendungen die Verwendung von http Sessions notwendig macht.
Ich freue mich auf deine Fragen im Kommentarbereich!
Hat dir der Artikel gefallen? Dann folge uns doch am besten gleich auf Facebook!
Markus
20. Oktober 2016 at 15:29Toller und übersichtlicher Artikel! Machst du so einen Artikel evlt. auch für Https?
Vielen Dank!
Kim Peter
21. Oktober 2016 at 9:45Hallo Markus, ich danke dir! Sobald ich herausgefunden habe wie https funktioniert, werde ich ein Artikel drüber schreiben. Viele Grüße Kim
Martin
6. November 2019 at 13:34Schöne Erklärung.
Kim Peter
12. November 2019 at 14:07Dankeschön!
Choose a style: